Unternehmen arbeiten heute mehr und mehr mit verschiedenen Anwendungen, welche den jeweiligen Geschäftsbetrieb digital abbilden. Diese Anwendungen verarbeiten verschiedenste Arten von Daten wie z.B. Kundendaten, Bestellungen oder Anfragen. Diese Daten sind essenziell wichtig für den Geschäftsbetrieb und müssen daher besonders geschützt werden.
Daten gibt es in verschiedenen Formen…
- Dateien
- In verschiedenen Dateiformaten
- pdf, xlsx, doc, txt, log uvm.
- Datenbanken
- Strukturierte Daten in Tabellen
- Spalten = Attribute
- Zeilen = Einträge
- Strukturierte Daten in Tabellen

↔️ Backups von Dateien mit rsync
Um Dateien zu sichern kopieren wir sie auf einen anderen Datenträger. Dieser Datenträger kann eine externe Festplatte oder die Festplatte eines anderen Serversystems sein.
Bei diesem Vorgang hilft uns der rsync Befehl. Mit Hilfe von rsync können Dateien schnell und einfach zwischen zwei Ordnern synchronisiert werden. Hierbei achtet das Programm darauf bei regelmäßigen Synchronisationen immer nur neue oder veränderte Dateien erneut zu übertragen, um den Vorgang so effizient wie möglich zu machen - was gerade bei großen Datenmengen sehr wichtig ist.
Aufgabe 1 - Zwei Ordner synchronisieren
Erstellen Sie zwei Ordner und befüllen Sie einen der beiden mit ein paar Dateien - die Dateien können leer sein. Die Ordnerstruktur müsste nun ungefähr so aussehen:
.
├── dir1
│ ├── file1.txt
│ ├── file2.txt
│ └── file3.txt
└── dir2
Recherchieren Sie wie die Dateien im Ordner dir1 in den Ordner dir2 mit Hilfe des rsync Befehls synchronisiert werden können. Nachdem Sie die Dateien ein mal Synchronisiert haben, ändern Sie den Inhalt einer der Dateien ab oder legen Sie eine neue Datei an und synchronisieren Sie die Ordner erneut.
Aufgabe 2 - Dateien archivieren
Wenn Dateien voraussichtlich erstmal nicht mehr gebraucht werden bzw. nicht dauerhaft auf Abruf bereit stehen müssen, kann es sich anbieten diese Dateien in einem Archiv zu komprimieren. Dadurch nehmen die Dateien weniger Speicherplatz ein. Wenn man wieder auf die Dateien aus diesem Archiv zugreifen möchte, müssen diese zunächst entpackt werden.
Es gibt unterschiedliche Archiv-Formate wie zum Beispiel .zip, .rar oder .tar.gz. Unter Linux gibt es den tar Befehl, welcher es ermöglicht Dateien in ein Archiv zu verpacken und entpacken.
Recherchieren Sie wie mit Hilfe des tar Befehls der Ordner dir1 in ein .tar.gz Archiv verpackt werden kann.
Komprimierung
Nachdem Sie herausgefunden haben wie das Archivieren mit Hilfe des tar Befehls funktioniert, können Sie nun die Komprimierung testen. Laden Sie sich dafür mit dem folgenden Befehl eine Datei herunter.
Datei herunterladen: wget akmnn.de/itadm/downloads/single_subnet.pkt
Nachdem Sie die Datei heruntergeladen haben, verschieben Sie sie in den dir1 Ordner. Archivieren Sie den Ordner nun erneut und prüfen Sie wie viel Speicherplatz durch die Komprimierung eingespart werden konnte. Mit Hilfe des du Befehls können Sie sich den Speicherplatzverbrauch der Ordner anzeigen lassen. Mit ls -l können Sie sich den Speicherplatzverbrauch von Dateien anzeigen lassen.
📤 Database Dumps
Eine Datenbank speichert Daten in Form von Tabellen, welche klaren Strukturen unterliegen. Jede Spalte ist vordefiniert mit dem jeweiligen Datentyp (String, Integer, Boolean…), ggf. einem Standardwert, ob der Wert zwingend notwendig ist oder optional uvw. Bei der Sicherung einer Datenbank müssen daher nicht nur die Datenbankeinträge (Zeilen) sondern die gesamte Datenstruktur (Spalten) gesichert werden.
Dafür bieten verschiedene Datenbanksysteme an sogenannte Database Dumps zu erstellen. Database Dumps sind Dateien, welche zum einen die Datenstruktur (also die Definition der Tabellen und deren Spalten) sowie die darin gespeicherten Daten enthalten. Diese Informationen werden in Form von SQL festgehalten. SQL (Structured Query Language) ist eine von vielen Datenbanksystemen verwendete Sprache, um zum einen die Datenstruktur zu definieren und zum anderen gezielt Daten aus dieser abzufragen.
Die SQL Dateien des Database Dump beinhalten somit ein komplettes Abbild der Datenbank und können im Notfall dazu verwendet werden, um die Datenbank wiederherzustellen.
🖖 RAID
Backups von Dateien und Daten sind im Grunde das Kopieren dieser auf einen anderen Datenträger, damit im Falle eines Datenverlustes, die Daten wiederhergestellt werden können. Es gibt unterschiedlichste Gründe für einen Datenverlust wie z.B. die fehlerhafte Bedienung einer Anwendung oder eine Festplatte geht kaputt.
Vor dem Ausfall einer Festplatte kann man sich mit einem sogenannten RAID schützen. RAID steht für redundant array of independent disks und meint dass mehrere Festplatten in einem Verbund zusammengefasst werden, sodass sie gemeinsam als ein logischer Datenträger agieren. Dieser Verbund kann je nach RAID Level dafür eingesetzt werden, besonders ausfallsicher oder auch performant zu sein.
Die verbreitesten RAID Level
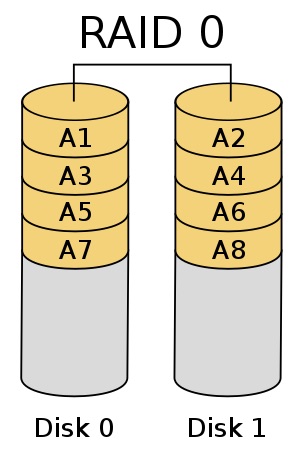
RAID 0 - Striping
Beim RAID 0 werden sämtliche Daten auf zwei Festplatten verteilt. Dadurch ist der Festplattenverbund performanter aber auch noch anfälliger für Ausfälle!
Wenn eine der beiden Festplatten ausfällt, sind auch die Daten der anderen Festplatte unbrauchbar. Somit hat man beim Ausfall einer Festplatte einen kompletten Datenverlust. Dafür ist der Verbund jedoch performanter, da die Input/Output Performance beider Festplatten nahezu addiert werden kann.
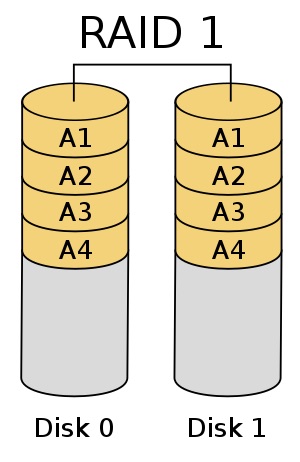
RAID 1 - Mirroring
Beim RAID 1 werden sämtliche Daten auf beiden Festplatten gespeichert. Dadurch hat man immer zwei komplett identische Festplatten mit den selben darauf gespeicherten Daten, wodurch die Ausfallsicherheit erhöht wird. Fällt eine Festplatte aus, macht die andere einfach weiter.
Dafür dass die Ausfallsicherheit beim RAID 1 erhöht wird, senkt sich im Gegenzug die Kapazität des Verbunds. Da auf beiden Festplatten die selben Daten gespeichert werden, halbiert sich die Gesamtkapazität der beiden Festplatten.
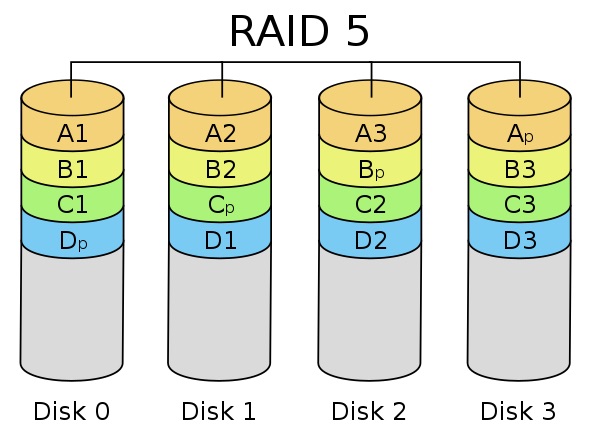
RAID 5 - Leistung + Parität
Beim RAID 5 werden die Daten ähnlich wie beim RAID 0 auf verschiedene Festplatte aufgeteilt. Zusätzlich wird hierbei eine der Festplatten genutzt, um Paritätsinformationen abzuspeichern.
Die Paritätsinformationen dienen der Fehlererkennung und -behebung. Sollte eine der Festplatten ausfallen, können sämtliche Daten mit Hilfer der Paritätsinformationen wiederhergestellt werden.
Das RAID 5 profitiert zum einen vom Striping (RAID 0) sodass es performanter ist als eine gewöhliche Festplatte zu betreiben also auch von der Ausfallsicherheit durch die Fehlererkennung und -behebung.
Unüblichere RAID Level
Es gibt eine Liste weiterer RAID Level mit verschiedenen Herangehensweisen. Eine Liste unüblicherer RAID Level finden Sie hier